Guide & Tutorial Elasticsearch : Elasticsearch est un serveur de recherche distribué similaire à Apache Solr, axé sur les grands ensembles de données, la configuration sans schéma et la haute disponibilité. Utilisant la bibliothèque Apache Lucene (également utilisée dans Apache Solr), Elasticsearch permet des recherches puissantes en texte intégral, l’autocomplétion, la recherche « morelikethis », une fonctionnalité multilingue, ainsi qu’une requête de recherche étendue DSL.
L’architecture sans schéma d’Elasticsearch offre aux développeurs une flexibilité intégrée ainsi qu’une facilité de configuration. Cette architecture permet à Elasticsearch d’indexer et de rechercher du contenu non structuré, ce qui le rend parfaitement adapté aux petits projets comme aux grands entrepôts de données – même avec des pétaoctets de données non structurées.
Ce tutoriel vous permettra d’utiliser les fonctionnalités étonnantes d’Elasticsearch et de construire des projets pour simplifier les opérations, même sur de grands ensembles de données.
Ce guide ultime commence par la création d’un service de recherche web de type Google, vous permettant de générer vos propres résultats de recherche. Vous apprendrez ensuite comment construire un site web de commerce électronique en utilisant Elasticsearch, ce qui aidera les utilisateurs à rechercher et à réduire l’ensemble des produits qui les intéressent. Vous explorerez la partie la plus importante d’une recherche en fonction de divers paramètres, tels que la pertinence, la pertinence de la collection de documents, le mode d’utilisation de l’utilisateur, la proximité géographique et la pertinence du document pour sélectionner les meilleurs résultats.
Ensuite, vous découvrirez comment Elasticsearch gère le contenu relationnel pour des données du monde réel, même complexes. Vous apprendrez ensuite les capacités d’Elasticsearch en tant que plate-forme de recherche analytique puissante, qui, associée à certaines techniques de visualisation, peut produire une visualisation des données en temps réel.
Vous découvrirez également comment améliorer la qualité de votre recherche et élargir le champ des correspondances en utilisant différentes techniques d’analyse. Enfin, ce tutoriel sur la recherche elasticsearch couvrira les différentes capacités géographiques de la recherche afin de rendre vos recherches similaires à des scénarios réels.
Sommaire
Tutorial Elastic Search : Ce dont vous avez besoin pour ce guide
Ce dont vous avez besoin pour ce guide
Vous aurez besoin des outils suivants pour construire les projets et exécuter les requêtes de ce tuto elasticsearch:
cURL
cURL est un outil de ligne de commande open source disponible sous Windows et Unix. Il est largement utilisé pour communiquer avec des interfaces web. Comme toute communication avec Elasticsearch peut se faire par le biais de protocoles REST standard, nous utiliserons cURL tout au long de ce livre pour communiquer avec Elasticsearch. Le site officiel de cURL est http://curl.haxx.se/download.html.
Elastic Search
Vous devez installer Elasticsearch à partir de son site officiel, ICI. Lorsque ce livre a été écrit, la dernière version d’Elasticsearch disponible était la 1.0.0, je vous recommande donc d’utiliser celle-ci. La seule dépendance d’Elasticsearch est Java 1.6 ou ses versions supérieures. Une fois que vous vous êtes assuré d’avoir installé Java, téléchargez le fichier ZIP d’Elasticsearch.
Il suffit d’écrire « bin\elasticsearch.bat » et de taper sur la touche entrée. Elasticsearch est en train de faire tourner une grappe, et elle devrait être prête dans un instant ou deux.
Une fois qu’elle est prête, vous pouvez arrêter le nœud en appuyant simplement sur CTRL + C simultanément. Pour s’assurer qu’il fonctionne correctement, nous allons
essayer de lui adresser une requête HTTP.
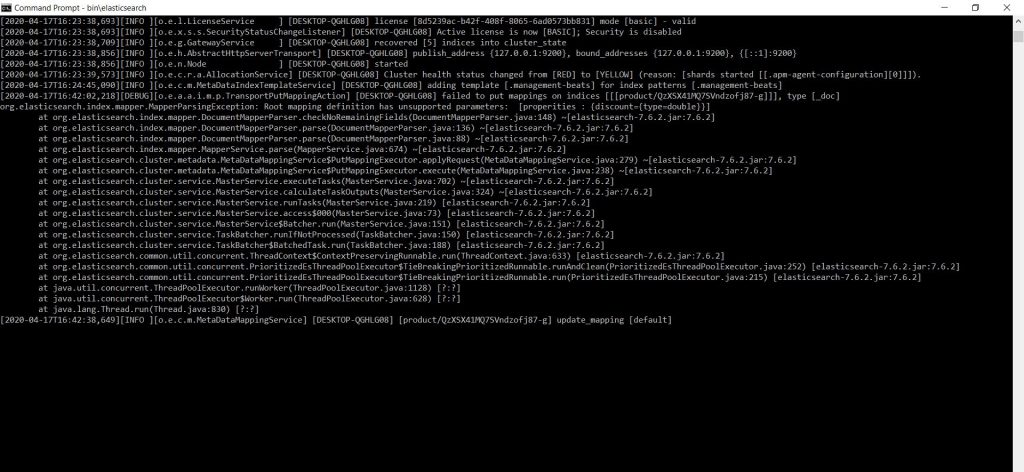
Nous pouvons le faire en contactant le port 9200 sur localhost, qui est le point terminal par défaut du cluster Elasticsearch.
N’importe quel client HTTP fera l’affaire, et le point de terminaison restera le même. Je vais utiliser un navigateur pour simplifier les choses. Alors, allez sur le navigateur, et naviguez jusqu’à http://localhost:9200

Kibana (facultatif)
Maintenant qu’Elasticsearch a été mis en place, il est temps d’installer Kibana Avant de commencer, je veux juste mentionner que si vous utilisez l’approche Docker, alors vous n’avez pas besoin d’installer Kibana, car il est déjà disponible sur localhost sur le port 5601. Les étapes d’installation de Kibana sont très similaires à ce que vous avez vu précédemment lorsque nous avons installé Elasticsearch. Tout d’abord, allez sur http://elastic.co dans votre navigateur. Ensuite, allez dans le menu « Produits » et cliquez sur « Kibana » sur la nouvelle page.
Une fois l’archive téléchargée, il vous suffit de l’extraire. Nous allons ouvrir l’invite de commande et naviguer jusqu’à l’archive extraite. La commande de démarrage de Kibana est similaire à la commande de démarrage d’un nœud de recherche élastique. Alors écrivons « bin\kibana » et appuyons sur Entrée. Cela va démarrer un serveur web sur localhost au port 5601 et essayer de contacter un cluster Elasticsearch sur localhost au port 9200.
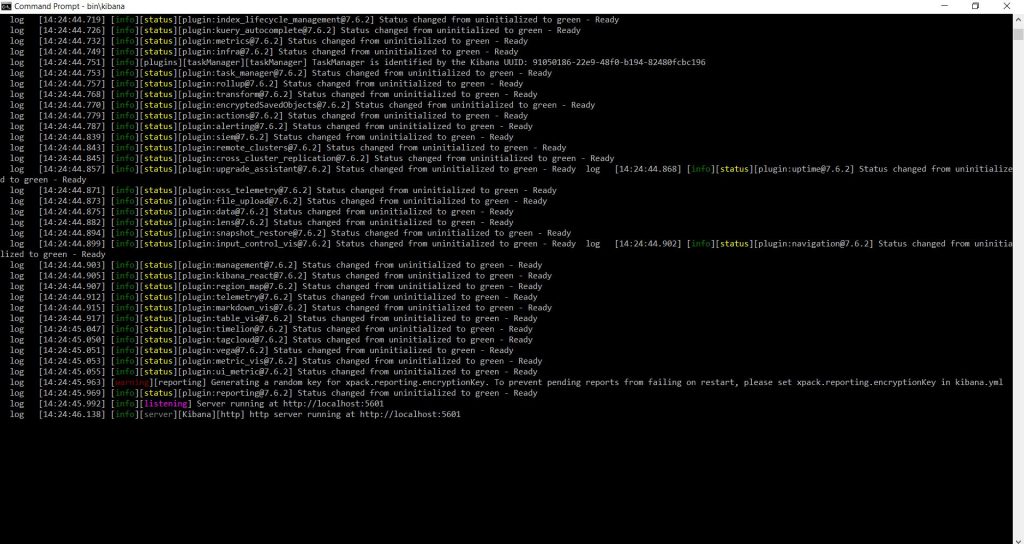
L’un des objectifs fondamentaux de la conception d’Elasticsearch est sa grande configurabilité, associée à des configurations par défaut optimales qui vous permettent de démarrer en douceur. Il vous suffit donc de lancer Elasticsearch.
Vous n’avez pas besoin d’apprendre des concepts de configuration complexes, du moins pour commencer. Notre serveur de recherche est donc opérationnel dès maintenant.
Conventions Dans ce tutoriel
vous trouverez un certain nombre de styles de texte qui font la distinction entre différents types d’informations. Voici quelques exemples de ces styles et une explication de leur signification. Les mots de code dans le texte, les noms de tables de bases de données, les noms de dossiers, les noms de fichiers, les extensions de fichiers, les noms de chemin, les URL fictives, les entrées utilisateur et les poignées Twitter sont présentés comme suit : « Notez que pour la plupart des champs qui ont une valeur de chaîne, comme le sexe, le but de la visite, etc., nous ajoutons la définition du type de champ non_analysé ».
Un bloc de code est défini comme suit :
"query": "nausea fever" } }, "negative": { "multi_match": { "fields": [ "title", "content" ],
Toute entrée ou sortie en ligne de commande s’écrit comme suit :
curl -XPOST 'http://localhost:9200/wiki/articles/' -d @India.json
Si vous avez un problème avec un aspect quelconque de ce guide, vous pouvez nous contacter ou redigier un commentaire dans la section en bas.
La recherche sur le Web avec ElasticSearch ?
Les problèmes de recherche de texte sont l’un des principaux cas d’utilisation courante des applications web. Les développeurs du monde entier ont tenu à apporter une solution open source à ce problème. C’est ainsi que la révolution Lucene a eu lieu. Lucene est le cœur de la plupart des moteurs de recherche que vous voyez aujourd’hui.
Il accepte essentiellement le texte à rechercher, le stocke sous une forme ou une structure de données facile à consulter (index inversé), puis accepte divers types de requêtes de recherche et renvoie un ensemble de résultats correspondants. Après la première révolution de la recherche, est venue la deuxième. De nombreuses solutions de recherche basées sur des serveurs, comme Apache SOLR, ont été construites sur Lucene et ont marqué la deuxième phase de la révolution de la recherche.
Ici, une puissante enveloppe a été créée pour servir d’interface aux utilisateurs du web qui voulaient indexer et rechercher du texte de Lucene. De nombreux outils puissants, notamment SOLR, ont été développés à ce stade de la révolution. Certains de ces cadres de recherche étaient également capables de fournir des fonctionnalités de base de données de documents. Puis, la phase suivante de la révolution de la recherche est arrivée, qui est toujours en cours. L’objectif de cette phase est de fournir des solutions de mise à l’échelle pour la pile existante.
Elasticsearch est un moteur de recherche et d’analyse qui fournit une puissante enveloppe à Lucene ainsi qu’une base de données de documents intégrée et fournit diverses solutions de mise à l’échelle. La base de données de documents est également mise en œuvre à l’aide de Lucene.
Bien que les concurrents d’Elasticsearch disposent de fonctionnalités plus avancées, ces outils manquent de simplicité et de la large gamme de solutions de mise à l’échelle qu’offre Elasticsearch. Nous pouvons donc constater qu’Elasticsearch est le point le plus avancé auquel la révolution de la recherche a atteint et qu’il représente l’avenir de la recherche textuelle.
Ce chapitre vous emmène sur la voie de la construction d’un serveur de recherche simple et évolutif. Nous verrons comment créer un index et y ajouter des documents, et nous essaierons certaines caractéristiques essentielles telles que la mise en évidence et la pagination des résultats. Nous aborderons également des sujets tels que le paramétrage d’un analyseur pour notre texte et l’application de filtres pour éliminer les caractères indésirables tels que les balises HTML, etc.
Voici les sujets importants que nous allons aborder dans ce chapitre :
- Déploiement de la recherche élastique
- Le concept de la tête de l’assurance-chômage : tessons et répliques
- Index – cartographie des types
- Analyseurs, filtres et tokenizers
- Le chef UI
On commence, explorons Elasticsearch en détail.
Communiquer avec le serveur Elasticsearch
cURL sera notre outil de choix que nous utiliserons pour communiquer avec Elasticsearch. Elasticsearch suit un protocole de type REST pour son API web exposée.
Certains de ses caractéristiques sont les suivantes :
- PUT : La méthode HTTP PUT est utilisée pour envoyer des configurations à Elasticsearch.
- POST : La méthode HTTP POST est utilisée pour créer de nouveaux documents ou pour effectuer
une opération de recherche. Si l’indexation des documents se fait avec succès en utilisant
POST, Elasticsearch vous fournit un identifiant unique qui pointe vers le fichier d’index. - GET : La méthode HTTP GET est utilisée pour récupérer un document déjà indexé. Chaque document possède un identifiant unique appelé « doc ID » (abréviation de « document’s ID). Lorsque nous indexons un document en utilisant POST, il fournit une identification du document, qui peut être utilisé pour retrouver le document original.
- DELETE : La méthode HTTP EFFACER est utilisée pour effacer des documents de la Indice de recherche élastique. La suppression peut être effectuée sur la base d’une requête de recherche ou en utilisant directement le document d’identification.
Pour spécifier la méthode HTTP dans cURL, vous pouvez utiliser l’option -X, par exemple,
CURL -X POST http://localhost/
JSON est le format de données utilisé pour communiquer avec Elasticsearch. Pour spécifier les données dans cURL, nous pouvons les spécifier dans les formulaires suivants :
- Une ligne de commande : Vous pouvez utiliser l’option -d pour spécifier le JSON à envoyer dans la ligne de commande elle-même, par exemple : curl -X POST ‘http://localhost:9200/news/public/’ -d ‘{« time » : « 12-10-2010 »}
- Un dossier : Si le JSON est trop long ou gênant pour être mentionné dans une ligne de commande, vous pouvez le spécifier dans un fichier ou demander à cURL de récupérer le JSON dans le fichier. Vous devez utiliser la même option -d avec un symbole @ juste avant le nom du fichier, par exemple : curl -X POST ‘http://localhost:9200/news/public/’ -d @file
Qu’est-ce que les Shards et replicas ?
Le concept de tesson est introduit dans Elasticsearch pour permettre une mise à l’échelle horizontale. L’échelle, comme vous le savez, a pour but d’augmenter la capacité du moteur de recherche, tant l’index la taille et la capacité du taux d’interrogation (interrogation par seconde). Supposons qu’une application puisse stocke jusqu’à 1 000 aliments et donne des performances raisonnables. Maintenant, nous devons augmenter la performance de cette application à 2.000 flux.
C’est là que nous cherchons à mettre à l’échelle solutions. Il existe deux types de solutions de mise à l’échelle :
- Mise à l’échelle verticale : Ici, nous ajoutons des ressources matérielles, telles que des plus de cœurs de processeurs ou de disques RAID pour augmenter la capacité de l’application.
- Mise à l’échelle horizontale : Ici, nous ajoutons des machines supplémentaires au système. Comme dans notre Par exemple, nous apportons une machine supplémentaire et nous donnons aux deux machines 1 000 nourrit chacun d’entre eux. Le résultat est calculé en fusionnant les résultats des deux machines. Comme les deux processus se déroulent en parallèle, ils ne mangeront pas plus de temps ou de bande passante.
Devinez quoi ! La recherche Elastic peut être mise à l’échelle aussi bien horizontalement que verticalement. Vous pouvez augmenter sa mémoire principale pour augmenter ses performances et vous pouvez simplement ajouter une nouvelle machine pour augmenter sa capacité. La mise à l’échelle horizontale est réalisée en utilisant le concept de sharding dans Elasticsearch. Comme Elasticsearch est un système distribué, nous devons répondre à nos préoccupations en matière de sécurité et de disponibilité des données.
Nous y parvenons en utilisant des répliques. Lorsqu’une réplique (taille 1) est définie pour un cluster comportant plus d’une machine, deux copies de l’ensemble de l’alimentation deviennent disponibles dans le système distribué. Cela signifie que même si une seule machine tombe en panne, nous ne perdrons pas de données et en même temps. La charge serait distribuée ailleurs. Un point important à mentionner ici est que le nombre de tessons et de répliques par défaut est généralement suffisant et que nous avons également la possibilité de modifier le nombre de répliques ultérieurement.
C’est ainsi que nous créons un index et que nous transmettons le nombre de shards et de replicas :
curl -X PUT "localhost:9200/news" -d '{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}'
Il convient ici de noter quelques éléments :
- L’ajout d’autres fragments primaires augmentera l’écriture dans l’ensemble de l’index
- L’ajout de répliques supplémentaires augmentera la durabilité de l’index et de la lecture tout au long, au prix de l’espace disque
Index-type mapping
Un index est une logique de regroupement où des flux de même type sont encapsulés ensemble. Un type est une logique de sous-groupe sous index. Pour créer un type sous index, vous devez choisir un nom de type. Comme dans notre cas, nous prenons le nom de l’index en tant que news et le nom du type en tant que public. Nous avons créé l’index à l’étape précédente et nous devons maintenant définir les types de données des champs que nos données contiennent dans la section de cartographie des types.
Consultez l’exemple suivant. Ici, le type de données de date prend le format de l’heure pour être aaaa/MM/jj HH:mm:ss par défaut :
curl -X PUT "localhost:9200/news/public/_mapping" -d '{
"public" :{
"properties" :{
"Title" : {"type" : "string" },
"Content": {"type" : "string" },
"DOP": {"type" : "date" }
}
}
}'
Une fois que nous appliquons la cartographie, certains aspects de celle-ci tels que les nouvelles définitions des champs peuvent être mis à jour. Cependant, nous ne pouvons pas mettre à jour certains autres aspects tels que le changement du type d’un champ ou la modification de l’analyseur attribué. Ainsi, nous savons maintenant comment créer un index et ajouter les cartographies nécessaires à l’index que nous avons créé. Il y a une autre chose importante dont vous devez vous occuper pendant l’indexation de vos données, c’est-à-dire l’analyse de nos données. Je suppose que vous connaissez déjà l’importance de l’analyse.
En termes simples, l’analyse consiste à décomposer le texte en une forme élémentaire appelée « tokens ». Cette forme symbolique est indispensable et doit être sérieusement prise en considération.
Elasticsearch dispose de nombreux analyseurs intégrés qui font ce travail pour vous. En même temps, vous êtes libre de déployer vos propres analyseurs personnalisés si les analyseurs intégrés ne servent pas votre objectif. Voyons l’analyse en détail et comment nous pouvons définir les analyseurs pour les champs.
Réglage de l’analyseur
Les analyseurs constituent une partie importante de l’indexation. Pour comprendre ce que font les analyseurs, considérons trois documents :
Document1 (tokens): { This , is , easy }
Document2 (tokens): { This , is , fast }
Document3 (tokens): { This , is , easy , and , fast }
Ici, des termes tels que Ceci, est, ainsi que et ne sont pas des mots-clés pertinents. Les chances qu’une personne souhaite rechercher de tels mots sont très faibles, car ces mots ne contribuent pas aux faits ou au contexte du document. Par conséquent, il est prudent d’éviter ces mots lors de l’indexation ou plutôt vous devriez éviter de rendre ces mots recherchables.
Ainsi, la symbolisation serait la suivante :
Document1 (tokens): { easy }
Document2 (tokens): { fast }
Document3 (tokens): { easy , fast }
Des mots tels que le, ou, ainsi que et sont appelés « mots d’arrêt ». Dans la plupart des cas, Ces derniers ont pour but de fournir un soutien grammatical et d’augmenter les chances que quelqu’un effectue une recherche basée sur ces mots sont minces. De plus, l’analyse et la suppression des mots vides est très dépend de la langue. Le processus de sélection/transformation des jetons interrogeables d’un document alors que l’indexation est appelée analyse.
Le module qui facilite c’est ce qu’on appelle un analyseur. L’analyseur dont nous venons de parler est un analyseur de mots vides. Par en utilisant le bon analyseur, vous pouvez minimiser le nombre de jetons consultables et et obtenir ainsi de meilleurs résultats.
Il y a trois étapes par lesquelles vous pouvez effectuer une analyse :
- Filtres de caractères : Le filtrage est effectué au niveau des caractères avant le traitement pour
- Des jetons. Un exemple typique est le filtre de caractères HTML. On pourrait donner un HTML à indexer pour Elasticsearch. Dans ce cas, nous pouvons fournir le filtre HTML CHAR pour faire le travail.
- Les tokenizers : La logique permettant de décomposer le texte en jetons est représentée dans cet état. Un exemple typique est celui des tokenizers d’espace blanc. Ici, le texte est décomposé en jetons en divisant le texte en fonction de l’occurrence de l’espace blanc.
- Filtres à jetons : En plus du processus précédent, nous appliquons un filtre à jetons. Dans ce Nous filtrons les jetons en fonction de nos besoins. Le filtre à jetons de longueur est un
- filtre à jeton typique. Un filtre à jeton de la longueur du type supprime les mots qui sont trop long ou trop court pour le courant.
Voici un organigramme qui illustre ce processus :
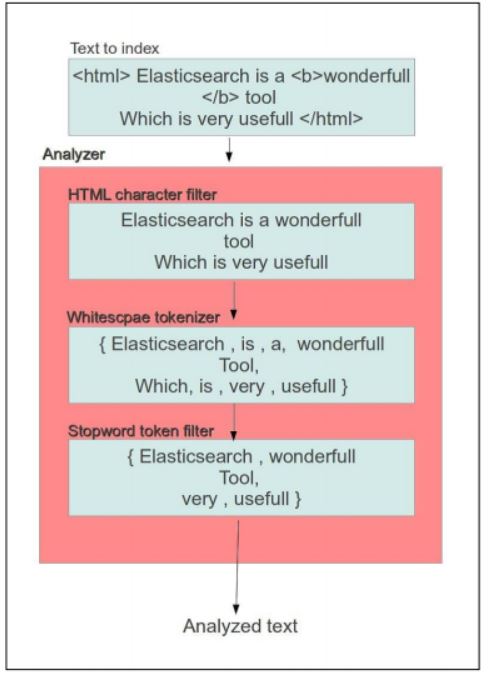
Il convient de noter que plusieurs de ces éléments peuvent être intégrés à chaque étape. Une combinaison de ces composants est appelée un analyseur. Pour créer un analyseur à partir des composants existants, il suffit d’ajouter la configuration à notre fichier de configuration Elasticsearch.
Types de filtres de caractères
Voici les différents types de filtres de caractères :
- le décapant HTML : Il permet de supprimer les balises HTML du texte.
- Filtre de caractères de mappage : Ici, vous pouvez demander à Elasticsearch de convertir un ensemble des caractères ou des chaînes de caractères à un autre ensemble de caractères ou de chaînes de caractères. Les options sont les suivants : « mappings » : [« ph=>f », « qu=>q »]
Types de tokenizers
Voici les différents types de jetons :
- Le tokenizer espace blanc : Un jeton de ce type divise le texte
à l’espace blanc. - Le tokenizer de bardeaux : Il existe des cas où vous souhaitez rechercher
texte avec deux mots consécutifs, comme l’Amérique latine. Dans les textes conventionnels
recherches, le latin serait un jeton et l’Amérique un jeton, donc vous
ne pourra pas se résumer au texte qui a ces mots l’un à côté de l’autre.
Dans le tokenizer de bardeaux, n nombre de jetons sont regroupés en un seul.
La génération de jetons pour un jeton de 2 grammes serait la suivante :
« L’Amérique latine est un endroit idéal pour aller en été »
=> { « Amérique latine » , « l’Amérique est » , « est un » , « un grand » ,
« lieu idéal » , « lieu de destination » , « aller » , « entrer » ,
« en été » } - Le tokenizer minuscule : Il convertit le texte en minuscules, ce qui permet
en diminuant la taille de l’indice.
Types de filtres à jetons (token filters)
Voici les différents types de filtres à jetons :
- Le filtre à jeton de mots vides : Un ensemble de mots sont reconnus comme des mots d’arrêt. Cela comprend des mots comme « est », « le », ainsi que « et » qui n’ajoutent pas de faits à la déclaration sur le plan grammatical. Un filtre à jetons pour les mots d’arrêt supprime les mots vides et permet ainsi de mener des actions plus des recherches efficaces.
- Le filtre à jeton de longueur : Il permet de filtrer les jetons qui ont une longueur supérieure à une valeur configurée.
- Le filtre à jeton de la tige : Le stemming est un concept intéressant. Il existe des
des mots tels que « apprendre », « apprendre », « appris », etc. qui se réfèrent à la même mots, mais sont ensuite dans des temps différents. Ici, il suffit d’indexer les
mot « apprendre » à n’importe quel temps. C’est ce que fait un filtre à jetons de stem. Il traduit les différents temps d’un même mot en un mot réel.
Analyseurs prêts à l’emploi
Une combinaison de filtres de caractères, de filtres de jetons et de jetons est appelée un analyseur. Vous pouvez créer votre propre analyseur en utilisant ces éléments de base, mais il y a aussi des analyseurs prêts à l’emploi qui fonctionnent bien dans la plupart des cas d’utilisation. Un analyseur à boule de neige est un analyseur de type boule de neige qui utilise le jeton standard avec la norme filtre, filtre en minuscules, filtre d’arrêt et filtre en boule de neige, qui est un filtre à tige.
Voici comment vous pouvez passer le réglage de l’analyseur à la recherche élastique :
curl -X PUT "http://localhost:9200/wiki" -d '{
"index" : {
"number_of_shards" : 4,
"number_of_replicas" : 1 ,
"analysis":{
"analyzer":{
"content" : {
"type" : "custom",
"tokenizer" : "standard",
"filter" : ["lowercase" , "stop" , "kstem"],
"char_filter" : ["html_strip"]
}
}
}
}}'
Ayant compris comment on peut créer un index et définir une cartographie de terrain avec les analyseurs, nous allons procéder à l’indexation de certains documents de Wikipédia.
Dans un but de démonstration, j’ai créé un simple script Python pour faire du JSON documents. J’essaie de créer des fichiers JSON correspondants pour les pages wiki du
pays suivants :
- Chine
- Inde
- Japon
- Les États-Unis
- France
Voici le script écrit en Python si vous voulez l’utiliser. Il prend en entrée deux arguments de ligne de commande : le premier est le titre de la page et le second est le lien :
import urllib2
import json
import sys
link = sys.argv[2]
htmlObj = { "link" : link ,
"Author" : "anonymous" ,
"timestamp" : "09-02-2014 14:16:00",
"Title" : sys.argv[1]
}
response = urllib2.urlopen(link)
htmlObj['html'] = response.read()
print json.dumps(htmlObj , indent=4)
Supposons que le nom du fichier Python soit json_generator.py. Voici comment nous l’exécutons : Python json_generator.py https://en.wikipedia.org/wiki/France > France. json’. Maintenant, nous avons un fichier JSON appelé France.json qui contient un échantillon de données que nous recherchons.
Je suppose que vous avez généré des fichiers JSON pour chaque pays que nous avons mentionné.
Comme nous l’avons vu précédemment, l’indexation d’un document une fois qu’il est créé est simple. À l’aide du script présenté ci-après, j’ai créé l’index et défini les correspondances :
curl -X PUT "http://localhost:9200/wiki" -d '{
"index" : {
"number_of_shards" : 4,
"number_of_replicas" : 1 ,
"analysis":{
"analyzer":{
"content" : {
"type" : "custom",
"tokenizer" : "standard",
"filter" : ["lowercase" , "stop" , "kstem"],
"char_filter" : ["html_strip"]}
}
}
}
}'
curl -X PUT "http://localhost:9200/wiki/articles/_mapping" -d '{
"articles" :{
"_all" : {"enabled" : true },
"properties" :{
"Title" : { "type" : "string" , "Analyzer":"content" ,
"include_in_all" : true},
"link" : { "type" : "string" , "include_in_all" : false ,
"index" : "no" },
"Author" : { "type" : "string" , "include_in_all" : false },
"timestamp" : { "type" : "date", "format" : "dd-MM-yyyy
HH:mm:ss" , "include_in_all" : false },
"html" : { "type" : "string" ,"Analyzer":"content" ,
"include_in_all" : true }
}
}
}'
Une fois que cela est fait, les documents peuvent être indexés comme ceci. Je suppose que vous avez le fichier India.json. Vous pouvez l’indexer comme :
curl -XPOST 'http://localhost:9200/wiki/articles/' -d @India.json
Indexez tous les documents de la même manière.
Utilisation de la recherche par expression
Nous avons ajouté certains documents à l’index que nous avons créé. Examinons maintenant quelques moyens d’interroger nos données. Elasticsearch fournit de nombreux types de requêtes pour interroger nos documents indexés. Parmi toutes celles qui sont disponibles, la recherche par chaîne de caractères est une excellente façon de commencer.
Le principal avantage de cette requête est qu’elle ne fera jamais d’exception. De plus, une simple requête par chaîne de caractères permet d’éliminer les parties non valables de la requête.
Elle couvre principalement ce qui est attendu de la plupart des moteurs de recherche. Elle prend OR de tous les termes présents dans le texte de la requête, bien que nous puissions changer ce comportement en AND. De plus, elle reconnaît tous les mots clés booléens dans le texte de la requête et effectue la recherche en conséquence. Pour plus de détails, vous pouvez consulter le site http://lucene.apache.org/core/2_9_4/queryparsersyntax.html.
Pour interroger un index Elasticsearch, nous devons créer une requête JSON. Une simple requête JSON est présentée ici :
{
"query": {
"simple_query_string": {
"query": "sms",
"fields": [
"_all"
]
}
}
Alors on arrive à la fin de la premiere session tutorial ElasticSearch, dans la formation suivante on va border les sections : pagination, Utilisation de la fonction de surlignage, UI, et plus. en attendant, on vous invite à partager l’article pour encourager l’équipe Rankiing !